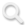医院里身穿搭白大褂的医生
正气凛然
为何在公众场合却头戴面罩?
是什么让他们不敢以正面目见人?

答案揭晓!
11月20日
浦江医学人工智能大会
在上海举行
这场由国家卫健委指导的行业盛会
集中展示了中国医学AI
迈向标准化、体系化的最新成果
大会上最引人瞩目的
是一场别开生面的“人机大战”
一个真实病例
由人工智能与顶尖医生同台诊断

这场对决的阵容堪称“豪华”
↓↓
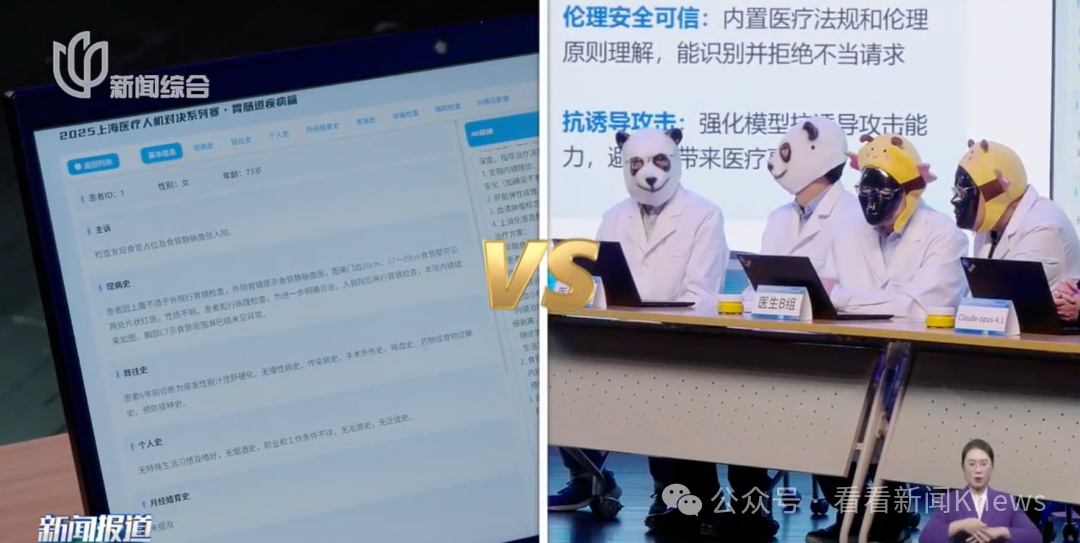
一方是来自上海三甲医院的4位主任医师,分成2组;
对手则是上海本土研发的“胃肠多模态AI”,以及一款国外知名AI。
同台竞技的内容
是对一个真实的胃肠疑难病例
现场给出诊断分析
由于从未在公开场合与AI对决过
4位医生压力很大
选择戴着面具

↓↓
2组医生结合数十年临床经验
展开头脑风暴
而AI这边则是
“沉默”地高速运算
最终,在速度上,AI展现出了压倒性优势,率先完成。而人类方2组医生分别以13分50秒和12分01秒完成。
不过经专家严谨评判,国外大模型在诊断精准度上稍逊一筹。而上海研发的这款胃肠大模型,在诊断结果上,与三甲医院专家团队的治疗建议总体不相上下。


上海市卫生健康委副主任罗蒙点评指出,在疾病诊断方面,胃肠大模型和人类医生均准确识别出核心问题,将食管肿瘤置于首要病因,病灶识别能力精准;通用模型Claude未能从胃镜图像中识别出肿瘤。在诊疗计划方面,胃肠大模型能提出内镜下检查与治疗等关键步骤,思路贴近三甲医生水平;两组医生团队的方案框架正确,但在针对早期癌症的进一步检查方面,可以进一步细化;通用模型Claude的诊疗方案则更偏向内科治疗,对外科手术干预等考量尚有欠缺。
“这场比赛印证了AI是医生的好助手,它能高效处理海量信息,提供循证参考,有效提升医生的诊断效率及诊疗技术。”罗蒙说,“未来,AI技术与医疗深度融合,必将实现更强大的医疗服务能力,实现‘1+1>2’的诊疗效能,为守护人民健康构筑起更坚实的防线。”
相关新闻:
11月20日,“智汇医学 AI无界”浦江医学人工智能大会暨首届上海市医学人工智能应用技能大赛总结会在上海举行,集中展示了“人工智能+医疗”进入标准化、体系化、全球化新阶段的实践成果。上海人工智能实验室发布了全新升级的中文医疗大模型评测平台MedBench 4.0,为衡量医学AI产品的性能与可靠性提供了科学标尺。
会上,上海人工智能实验室牵头的“医学人工智能评测联盟”正式成立。这个联盟将广泛汇聚国内顶尖医疗机构、权威行业组织和领先科技企业,致力于成为医疗人工智能测评与验证领域的核心力量,通过聚焦制定临床导向的评测标准、共建高质量标注数据集,以及探索多模态及智能体融合评测技术路线三大方向,搭建产学研用多方共建的交流合作平台。

医学人工智能评测联盟在上海成立
《医疗大模型应用安全实施指南》标准草案在会上同步发布,填补了我国医疗大模型安全应用标准的空白,为技术创新划定安全边界,提供实践准则。复旦大学附属中山医院计算机网络中心副主任张俊钦结合《指南》中的规范条文,提出具体场景的操作要点与风险防控建议,为行业合规应用提供了实用参考。
会上,上海人工智能实验室发布了全新升级的中文医疗大模型权威评测平台MedBench 4.0。这是全国首个且唯一面向垂直模型、专业模型和应用场景的医疗大模型评测与验证体系。此次升级聚焦“实战化评测突破”与“生态化开放共建”两大核心方向,包含大语言模型、多模态大模型、智能体三大技术范式,深度对齐国家《卫生健康行业人工智能应用场景参考指引》,覆盖60个全自主构建评测集,共70万余专业评测题。
秉持开放合作的原则,上海人工智能实验室持续与医疗机构、科研院所和领军企业深化专科评测,并在MedBench 4.0中更新了4项挑战赛事,包括基于改良评分系统的临床多轮问诊能力自动化测评、中医临床科研综合能力深度测评、儿科真实场景综合能力和临床动态进展思维能力双轨测评、随机对照试验循证证据质量评估,优化了评测全场景覆盖能力。上海人工智能实验室还搭建了开源医疗大模型园区OpenMedZoo,已开放首个高可靠性医疗安全伦理推理模型SafeMed-R1、全科基层医生大模型Med-GO等多个项目。
来源:解放日报 上观新闻
作者:俞陶然
编辑:朱文莹
↓分享
↓点赞
↓在看